
Imagen: Cemosa
¿Qué se puede hacer con los datos que pueden arrojarnos las carreteras?
Para quien siga este Blog, o conozca la iniciativa del proyecto REPARA2.0, sabrá que en el mismo existe una gran presencia del concepto “BIG DATA”, la recolección de datos, la generación de alertas, etc., todo ello centrado en el pavimento de las carreteras. Siguiendo esta línea, nos proponemos en la presente entrada a comentar distintos enfoques que, a pesar de quedar fuera de los objetivos del proyecto REPARA2.0, complementan sus desarrollos.
Vivimos un cambio tecnológico en el que los datos inundan nuestro entorno. Será cosa del “Internet de las Cosas”, los “Sistemas Ciber-físicos” o aquello de la “4ª Revolución Industrial”, pero todo lo que nos rodea tiene un marcado tono tecnológico. De ahí que profesiones más “tradicionales” como las ligadas a las infraestructuras tengan que saber adaptarse a las nuevas oportunidades. Adaptarse o desaparecer, ya nos avisó Darwin.
Pues bien, de la gran cantidad de datos que nos proporcionan los sistemas de monitorización, los datos meteorológicos, los datos de tráfico, los datos de inspección de las infraestructuras, las ordenes de trabajo de los equipos de mantenimiento, etc., pueden ayudarnos a mejorar el servicio en transporte por carretera, reduciendo el número de interrupciones, aumentando la seguridad vial y el confort, así como reducir los costes de mantenimiento, y por tanto, proporcionando un ahorro que puede conllevar a una inversión pública más eficiente.
El viaje desde la recolección de los datos, hasta la herramienta de ayuda a la toma de decisiones ha de estar plagado de desarrollos novedosos, en los cuales, un ingente número de grupos de investigación están trabajando.
El primero de los problemas al que hay que enfrentarse al trabajar con datos, es la organización, almacenamiento y la interoperabilidad entre las distintas fuentes de los mismos. No es de recibo tener que utilizar un esfuerzo cercano al 40% del total para conseguir organizar los datos y hacerlos digeribles para las metodologías desarrolladas. Los datos provenientes de las infraestructuras de carreteras deberían de estar organizados de una manera estandarizada, de tal manera que cualquiera que accediera a ellos pudiese utilizarlos. Esta estandarización enfocada a un trabajo colaborativo es la esencia del “Building Information Modelling” (BIM) tan famoso estos últimos años. No ha de quedarse en una simple representación 3D de las infraestructuras, sino en un almacén donde todos los datos, desde el diseño hasta la explotación, estuviesen disponibles. Con estructuras de datos en desarrollo como “IFC-Roads” esto se podría conseguir.
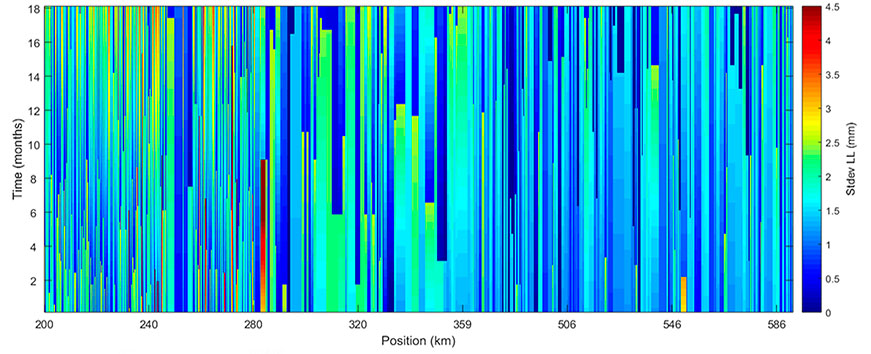
Una vez los datos están disponibles, se pueden desarrollar múltiples líneas de investigación. Por ejemplo, cruzando datos del estado de conservación de terraplenes, desmontes, puentes o el propio pavimento, con datos meteorológicos y de tráfico, se pueden obtener tendencias sobre cómo se comporta la infraestructura frente a la demanda de los usuarios o el efecto del cambio climático.
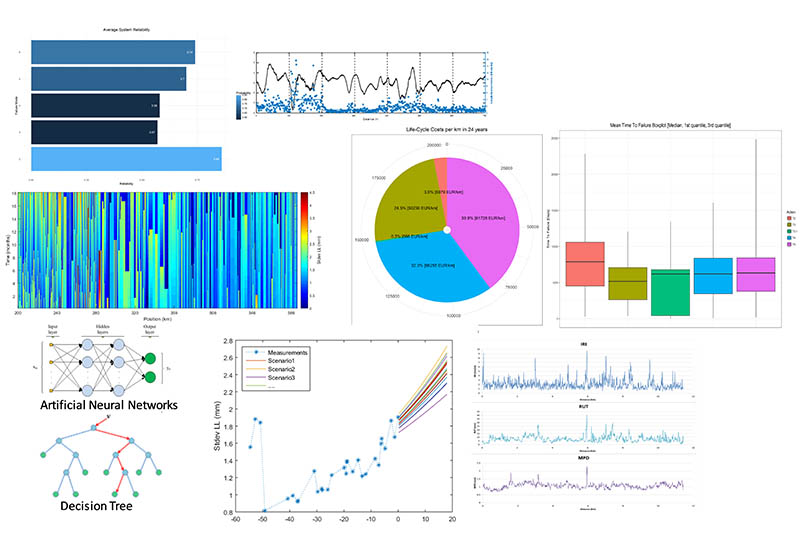 Imagen: CEMOSA
Imagen: CEMOSA
Observar las tendencias, es decir, poder predecir comportamiento a futuro, da un carácter estocástico a la toma de decisiones, pudiendo evaluar el riesgo asumido entre una u otra decisión relativa a la gestión de la carretera o las infraestructuras en general.
Una técnica que usa los datos para la gestión del mantenimiento, teniendo por objetivo el desarrollo de un mantenimiento predictivo eficaz, es la de conjuntar estudios de confiabilidad con los costes de la explotación de la carretera.
El estudio de la confiabilidad se lleva a cabo a partir de un análisis RAMS consistente en evaluar la fiabilidad, la disponibilidad, el mantenimiento y la seguridad de la infraestructura. Este tipo de análisis se lleva a cabo de forma habitual en la industria y en el mundo ferroviario, pero aún no está implantado en el mundo carretero. Por otro lado, el estudio de costes se lleva a cabo a partir de un análisis LCC donde se evalúan todos los costes en los que se incurrirá en una determinada infraestructura desde la etapa de diseño hasta la de demolición. Los costes de diseño y de demolición se pueden considerar fijos, siendo los costes variables, los costes de explotación y mantenimiento, dependientes de las variables estocásticas.
A partir de analizar todos los datos que nos puede proporcionar la carretera, el análisis RAMS nos proporcionará una probabilidad de fallo por cada elemento evaluado, que junto con el conocimiento del coste de reposición o mantenimiento de este elemento, se podrá calcular un coste de ciclo de vida teniendo en cuenta el carácter estocástico del coste.
Tras considerar este carácter estocástico ligado a la probabilidad de fallo, tomar la decisión entre diferentes estrategias de mantenimiento puede realizarse conociendo con mayor precisión el riesgo que se está asumiendo. Incluso, se puede introducir esta metodología dentro de un problema de optimización y poder así obtener políticas de mantenimiento predictivo optimizadas dentro de la gestión del sistema de carreteras.
Todos los desarrollos mencionados se están llevando a cabo por numerosos proyectos de investigación liderados por universidades, centros tecnológicos y empresas. Todos los avances están siendo prometedores. En un futuro próximo, con un uso inteligente de los datos de la carretera, se podrán desarrollar políticas de inversión en infraestructuras mucho más eficaces… y, ¿podremos dejar atrás aquello de malgastar?